
测试基础AI智能体实战

测试基础AI智能体实战
Pupper一、MD文档生成测试用例实战
Dify 中 迭代与循环的区别:
| 特性 | 迭代 (Iteration) | 循环 (Loop) |
|---|---|---|
| 核心定义 | 针对列表/数组数据中的每一项逐个执行相同的操作。 | 根据条件判断重复执行一段逻辑,直到条件不再满足。 |
| 处理对象 | 集合数据(如搜索结果列表、文档切片)。 | 逻辑状态(如“重试直到成功”、“递归搜索”)。 |
| 执行次数 | 预先确定的(等于列表中元素的数量)。 | 动态确定的(取决于条件何时满足,可能陷入死循环)。 |
| 典型场景 | 批量翻译一组句子、对搜索出的 5 条新闻分别做摘要。 | 引导 Agent 反思改进输出、不断重试 API 调用直到返回正确结果。 |
| 数据关系 | 每一项处理通常是独立的(也可配置为累积)。 | 后一次循环往往依赖前一次的结果或状态。 |
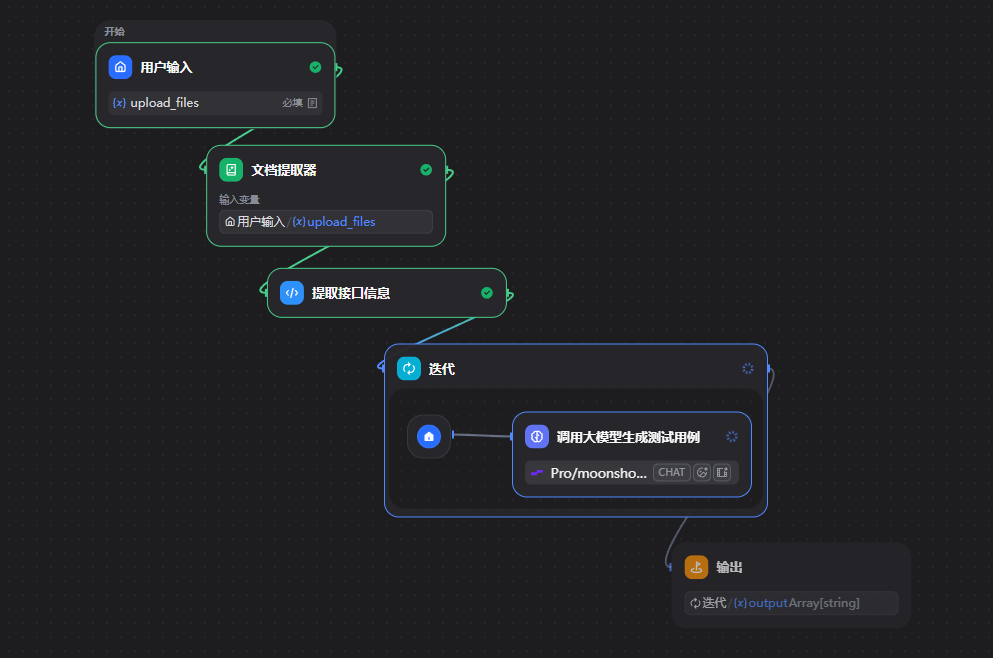
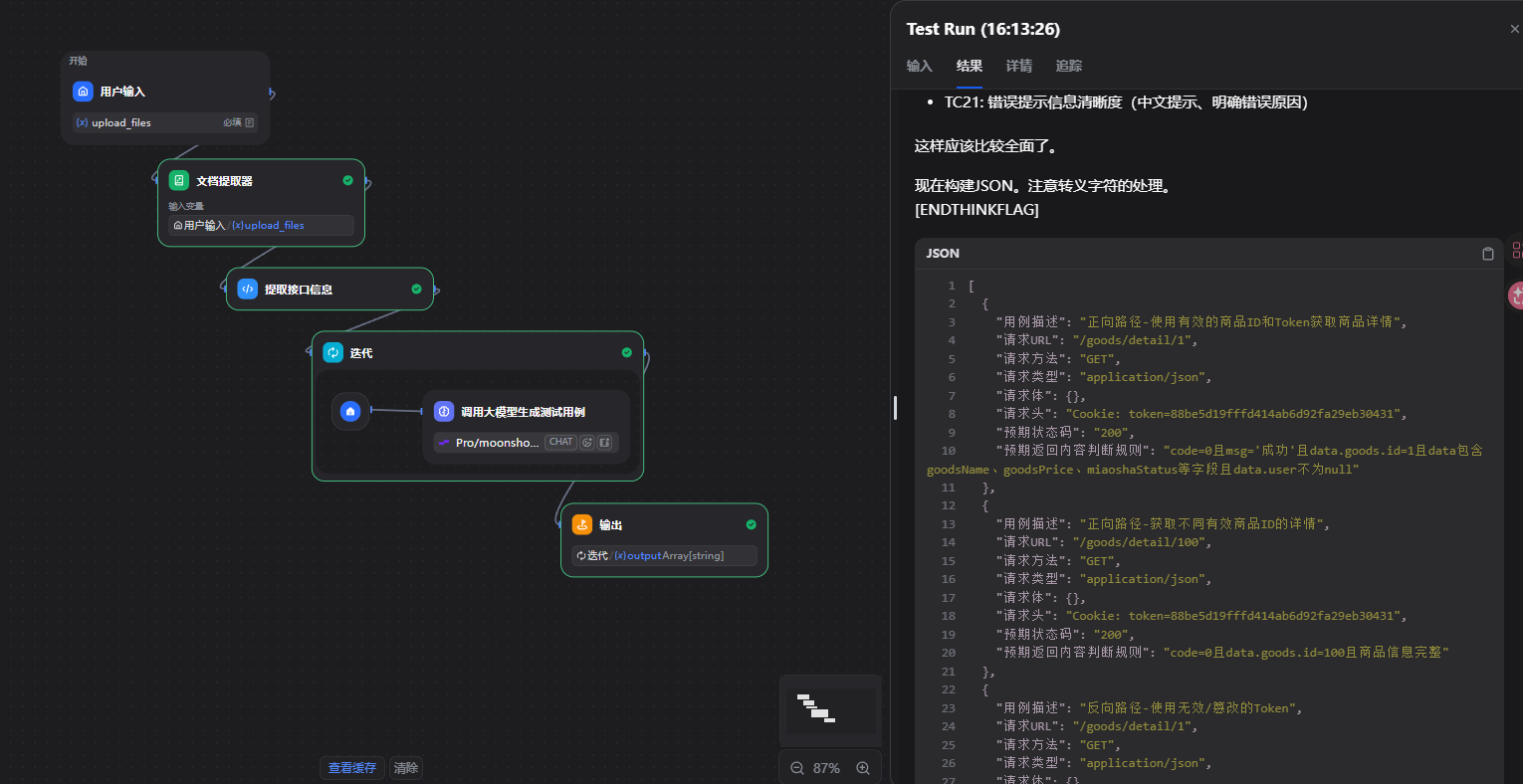
代码执行输出变量名称需要与执行代码中return 出来的值一致
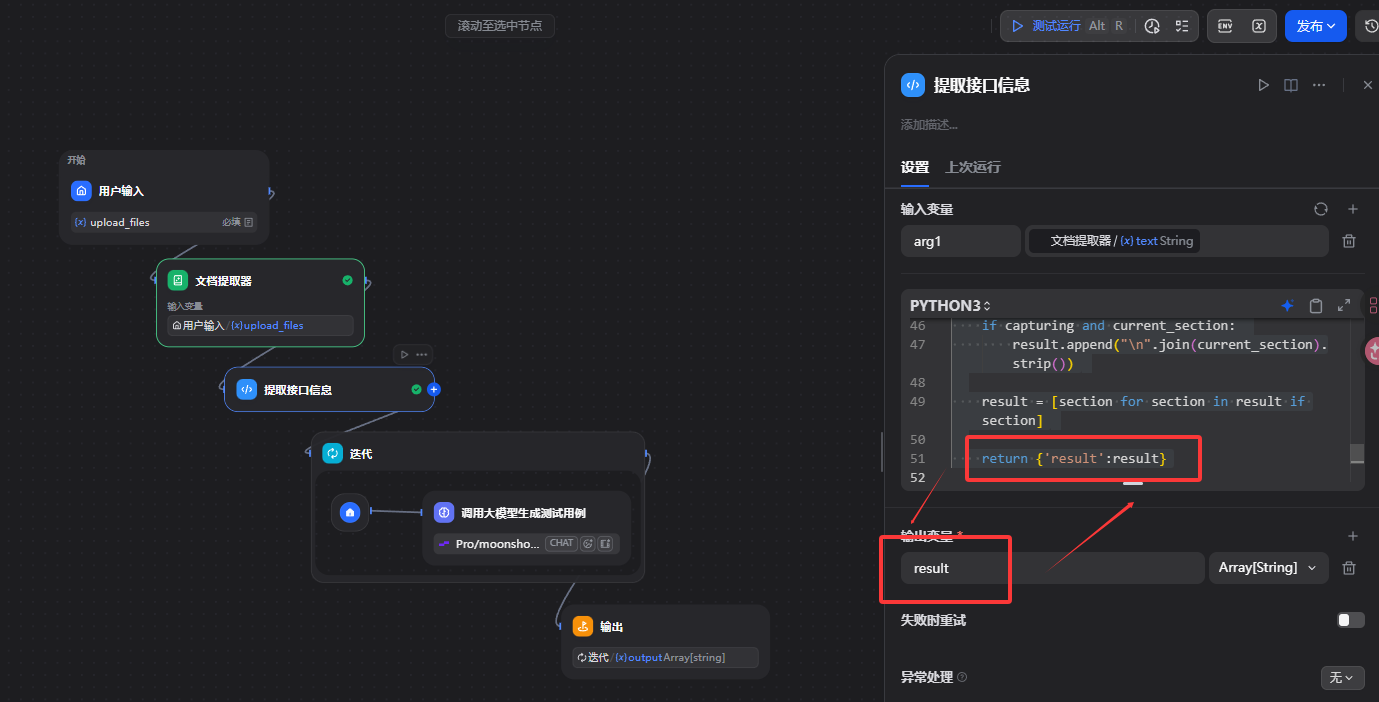
1 | from pathlib import Path |
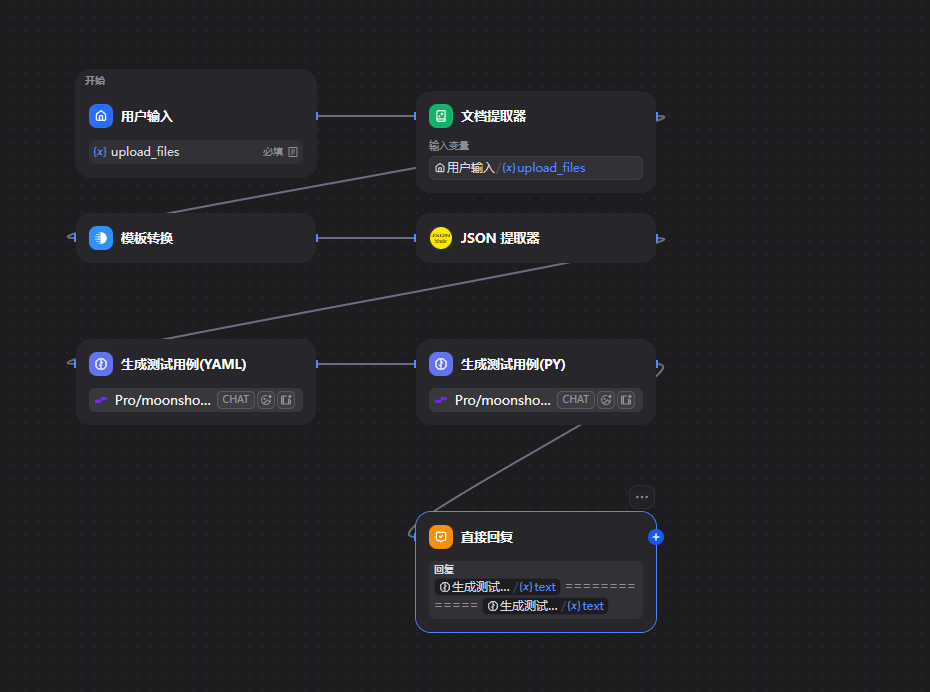
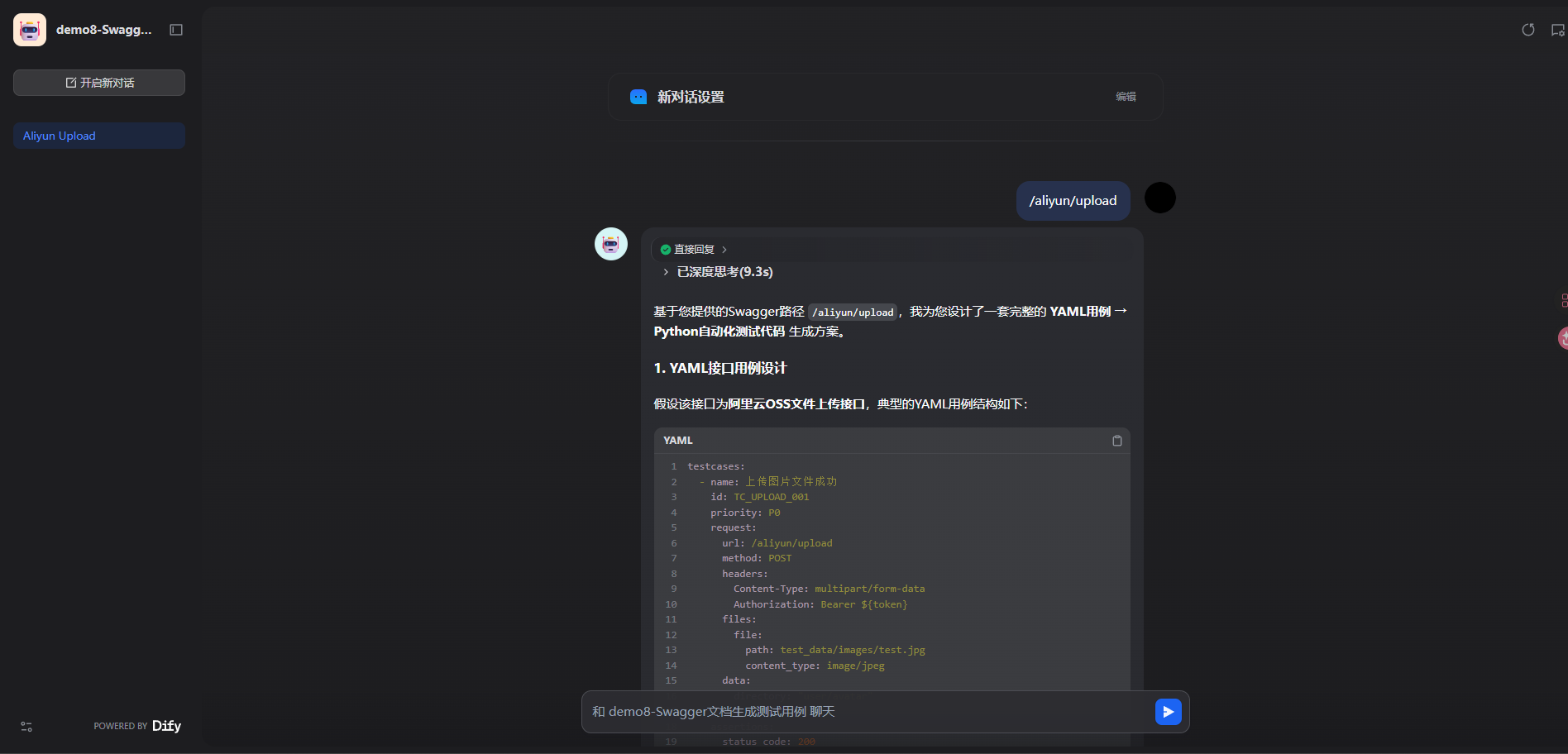
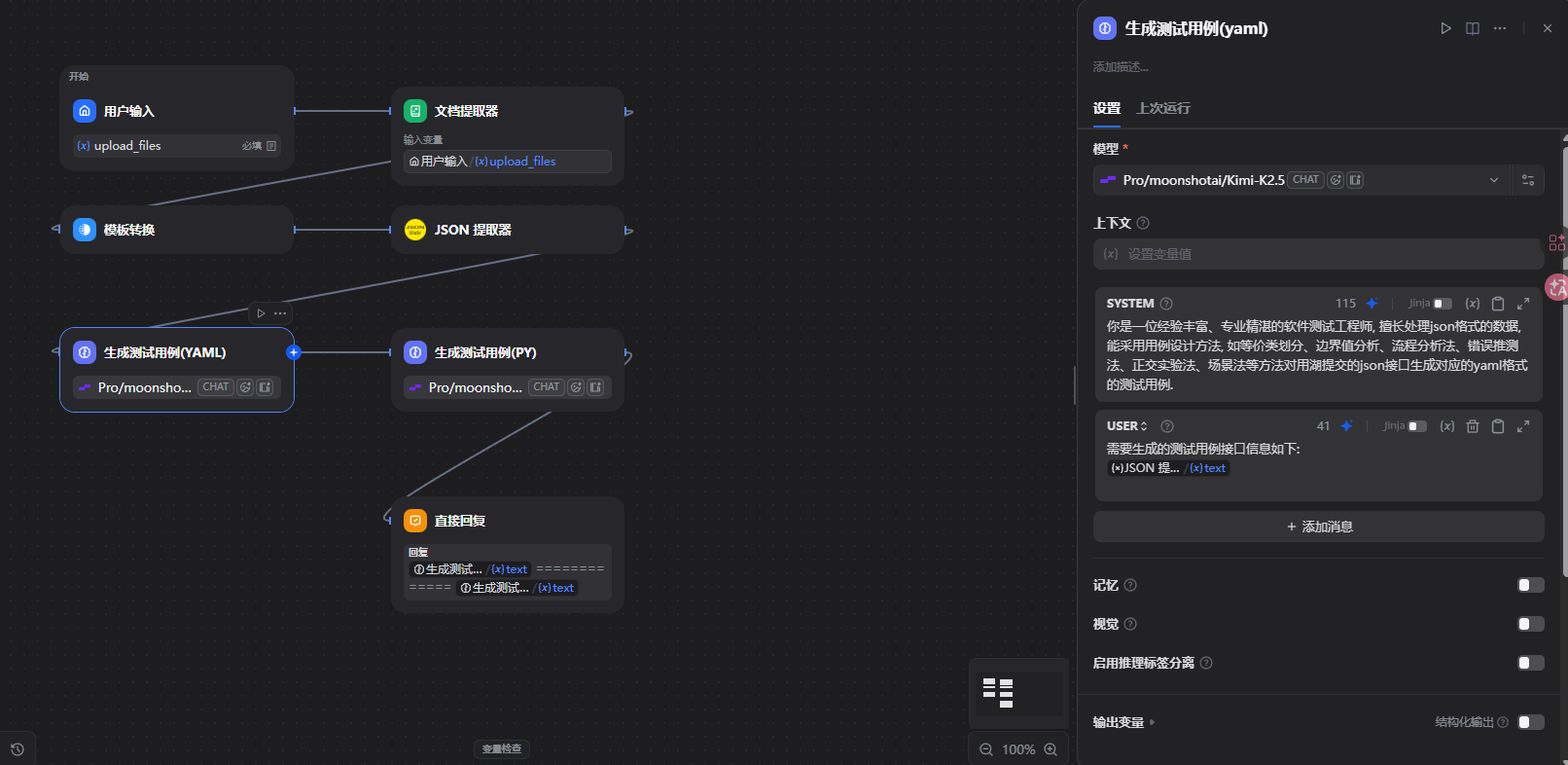
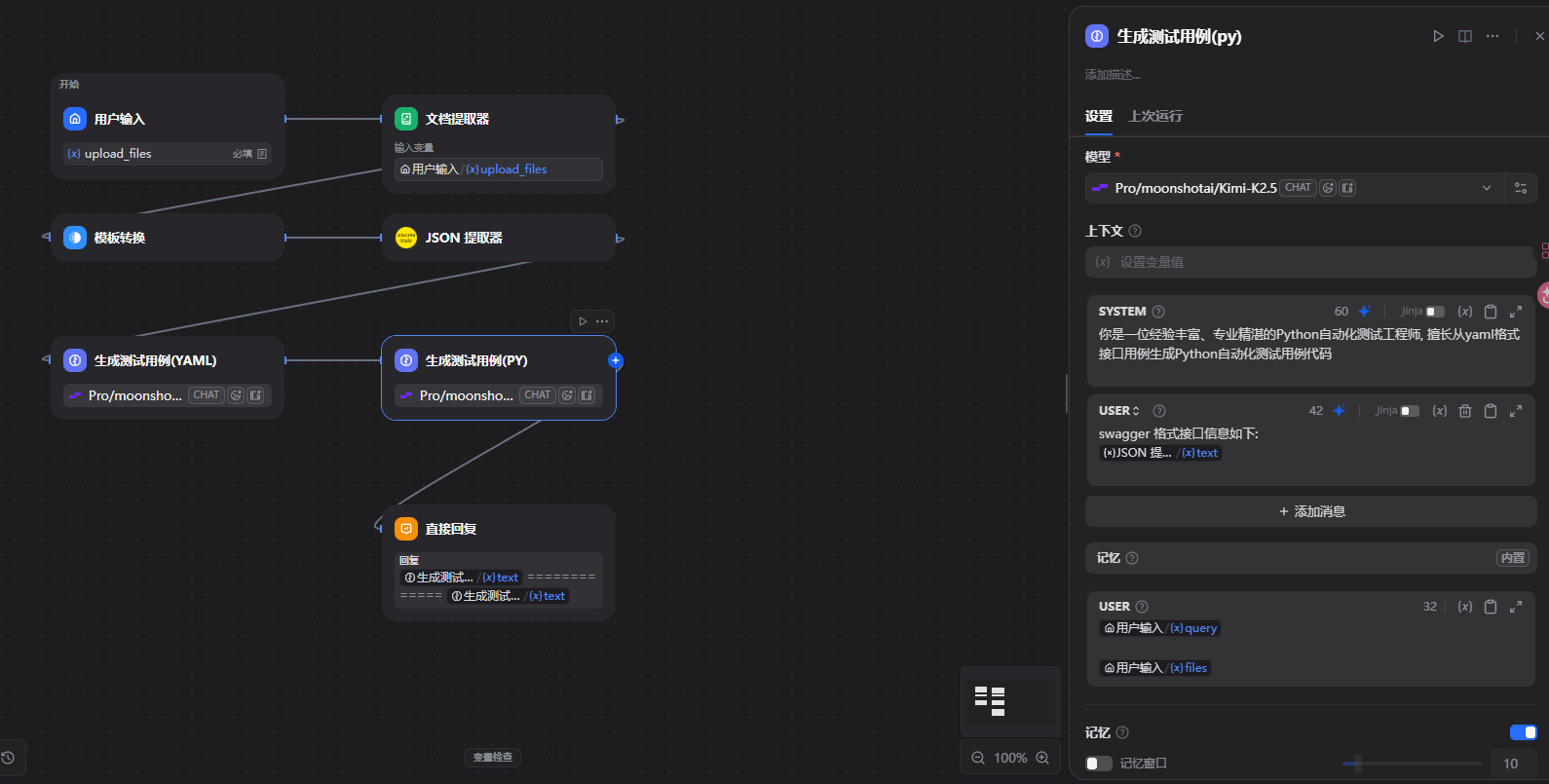
二、Swagger文档生成测试用例实战


喜欢这篇文章的人也看了




评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果



